Google BigQuery Connector
![]()
Overview
The Google BigQuery connector allows users to perform different operations on the Google BigQuery instance from Anypoint Platform. BigQuery is Google’s fully managed, petabyte scale, low cost analytics data warehouse. The connector exposes Google BigQuery operations by executing their API calls as per configuration. It supports various operations relate to Dataset, Table, Job, etc. Read through this user guide to understand how to set up and configure a basic flow using the connector.
Track features and API version updates using the Google BigQuery Connector Release Notes. Review the connector operations and see how they work by reviewing the technical reference alongside the demo applications
Introduction
This document assumes that user is familiar with Google BigQuery, Anypoint Connectors, and Anypoint Studio. To increase familiarity with Studio, consider completing a Anypoint Studio Tutorial. This page requires basic knowledge of Mule Key Concepts and Google BigQuery.
Software Requirements
For software requirements, visit the Connector Release Notes.
Installation
To install the connector in Anypoint Studio use the instructions in Add Modules to Your Project.
Additionally, we recommend to keep Studio up to date with its latest version.
Connector Namespace and Schema
While designing Mule application in Anypoint Studio, when user drag the connector from the palette onto the Anypoint Studio canvas, studio automatically populates the XML code with the connector namespace and schema location.
Namespace: http://www.mulesoft.org/schema/mule/bigquery
Schema Location: http://www.mulesoft.org/schema/mule/bigquery/current/mule-bigquery.xsd
Tip If you are manually coding the Mule application in Studio’s XML editor or another text editor, define the namespace and schema location in the header of your Configuration XML, inside the <mule> tag.
—– —————————————————————————————————————————————————————————————————————
<mule xmlns:bigquery="http://www.mulesoft.org/schema/mule/bigquery"
xmlns:http="http://www.mulesoft.org/schema/mule/http"
xmlns="http://www.mulesoft.org/schema/mule/core"
xmlns:doc="http://www.mulesoft.org/schema/mule/documentation"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.mulesoft.org/schema/mule/core http://www.mulesoft.org/schema/mule/core/current/mule.xsd
http://www.mulesoft.org/schema/mule/http http://www.mulesoft.org/schema/mule/http/current/mule-http.xsd
http://www.mulesoft.org/schema/mule/bigquery http://www.mulesoft.org/schema/mule/bigquery/current/mule-bigquery.xsd">
</mule>
Note: Use current in the schema path. Studio interprets this to
the current Mule version.
Maven Dependency Information
After downloading and installing the connector, following steps make the Google BigQuery connector available inside a Mule application for use and to package the application with connector. If using Anypoint Studio, it will do this automatically. For Maven dependency management, include this XML snippet in pom.xml file in the Mule project.
<dependency>
<groupId>com.mulesoft.connectors</groupId>
<artifactId>mule-bigquery-connector</artifactId>
<version>2.0.0</version>
<classifier>mule-plugin</classifier>
</dependency>
Configuration
Creating a New Project
To use the BigQuery connector in a Mule application project:
-
In Anypoint Studio, click File > New > Mule Project

Select Mule project from the dialog box. -
Enter project name and specify Runtime, API Implementation and Project Location if needed.
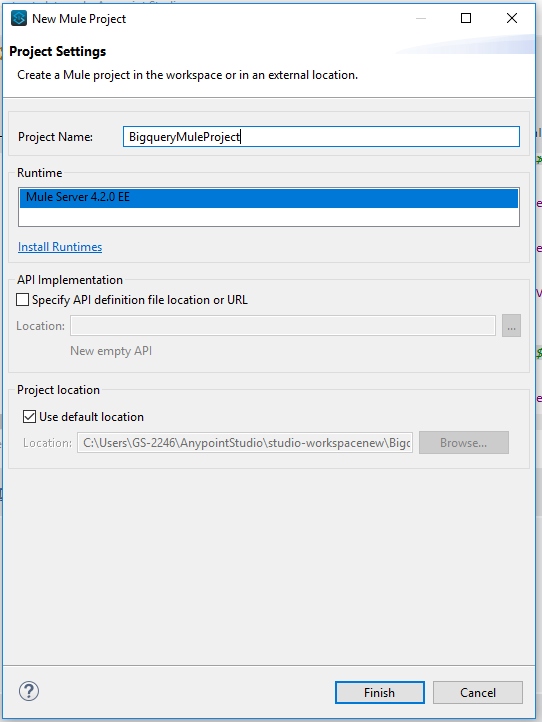
-
Click Finish to create the project
Configuring the BigQuery Global Element
Place the connector in the Mule flow as per the use case. To use the BigQuery connector in the Mule application, user must configure a global BigQuery element that is used by the Google BigQuery connector to authenticate. The BigQuery connector provides the following global configuration.
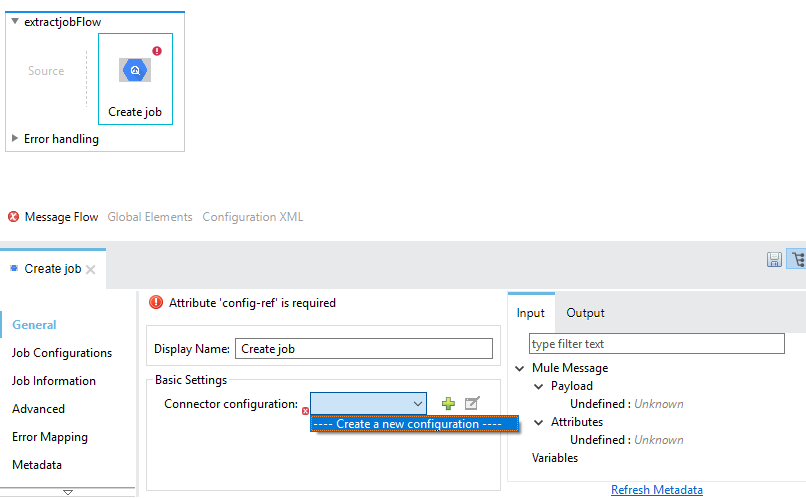
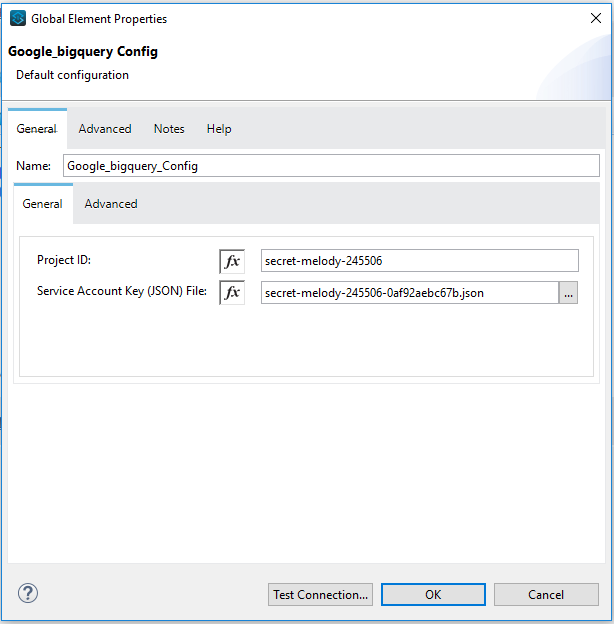
Authentication
To access BigQuery instance user needs to configure service account key as mentioned in below section.
SERVICE ACCOUNT KEY
Service accounts can be used by applications to access Google APIs
programmatically via OAuth 2.0. A service account uses an OAuth 2.0 flow
that does not require human authorization. Instead, it uses a key file
that only your application can access.
For Creating and managing service account keys, refer Google
Cloud.
Following parameters are required for SERVICE ACCOUNT KEY configuration:
| Field | Description |
|---|---|
| Project ID | Project ID of Google Cloud Platform’s project (If any) or create a new project on Google Cloud Platform. |
| Service Account Key (JSON) File | Associated with Google Cloud Platform’s Project. Download the file, place it in BASE_LOCATION_OF_PROJECT/src/main/resources folder and provide it's relative path. |
Understanding the Google BigQuery Connector
The Google BigQuery connector functions within a Mule application. Using the connector, Mule application can perform several operations that BigQuery exposes via their APIs. When building an application that connects with BigQuery user doesn’t have to go through the effort of custom-coding (and securing!) a connection. Rather, just drop a connector into the Mule flow, configure a few connection details and begin application running on BigQuery.
Google BigQuery Connector is used to connect to Google BigQuery service. Google BigQuery Connector is built using google-cloud-bigquery Java API client. It executes APIs exposed by Google BigQuery using configured parameters.
Google BigQuery connector is configured to authorize access to BigQuery resources. It requires Project ID and the location of the JSON key file for the Service Account authentication.
Note: All BigQuery connector operations returns Java objects defined in google-cloud-bigquery Java API client provided by Google. For more information about how to read data from these Java objects please refer Google BigQuery JavaDocs
The real value of the BigQuery connector is in the way you use it at design-time in conjunction with other functional features available in Mule.
-
DataSense DataSense extracts metadata for BigQuery standard response to automatically determine the data type and format that your application must deliver to, or can expect from, BigQuery. Mule does the heavy lifting of discovering the type of data you must send to, or be prepared to receive from BigQuery.
-
Transform Message Component This component’s integrated scripting language called DataWeave can automatically extract response metadata that you can use to visually map and/or transform to a different data format or structure. Essentially, DataWeave let’s you control the mapping between data types. For example, if you configure a BigQuery connector in your application, then drop a Transform Message component after the connector, the component uses DataWeave to gather information that DataSense extracted to pre-populate the input values for mapping. In other words, DataSense makes sure that DataWeave knows the data format and structure it must work with so you don’t have to figure it out manually. Mule developer can refer to BiqQuery Connector API docs and Google BigQuery JavaDocs for more information about complex input or return types.
Common Use Cases
-
Insert Data to BigQuery Table and Extract it to Google Cloud Storage
-
Load Data to BigQuery Table from Google Cloud and Perform Query
-
Insert Data to BigQuery Table, Perform Asynchronous Query and Get Query Result
Insert Data to BigQuery Table and Extract it to Google Cloud Storage
This use case demonstrates Inserting data into BigQuery Table and Extract it to Google Cloud Storage. It creates dataset and table, Insert data into it and Extract data to Google Cloud Storage. It also get the details of the extract job and check job execution status. Atlast, it deletes dataset and table once extract job complete execution.
-
In Anypoint Studio, click File > New > Mule Project, name the project, and click Finish.
-
In the search field, type Http and drag the HTTP Listener to the canvas.
-
Click the HTTP Listener, click the green plus sign to the right of Connector Configuration. On the next screen, add the host and port, click OK.
-
Provide Path to HTTP Listener (Example: /extractData)
-
On the Mule Palette, search for Create Dataset and drag it onto the canvas.
-
Provide appropriate dataset name and other fields.
-
Add Set Payload onto the canvas. Set below JSON for table fields/schema as expression to the payload value.
[{
"FieldName" : "Name",
"FieldType" : "STRING",
"fieldDescription" : "This is name",
"fieldMode" : "NULLABLE"
},
{
"FieldName" : "EmployeeID",
"FieldType" : "STRING",
"fieldDescription" : "This is Employee Id",
"fieldMode" : "NULLABLE"
},
{
"FieldName" : "Age",
"FieldType" : "INTEGER",
"fieldDescription" : "This is Age",
"fieldMode" : "NULLABLE"
},
{
"FieldName" : "ContactNumber",
"FieldType" : "STRING",
"fieldDescription" : "This is Contact Number",
"fieldMode" : "NULLABLE"
},
{
"FieldName" : "Designation",
"FieldType" : "STRING",
"fieldDescription" : "This is Designation",
"fieldMode" : "NULLABLE"
},
{
"FieldName" : "Salary",
"FieldType" : "FLOAT",
"fieldDescription" : "This is Salary",
"fieldMode" : "NULLABLE"
}
]
- We used following Table Schema:
| Field name | Field type |
|---|---|
| Name | String |
| EmployeeID | String |
| Age | Integer |
| ContactNumber | String |
| Designation | String |
| Salary | Float |
- Add Create Table onto the canvas. Provide Dataset Name, Table Name and map payload to the Table Fields using below Data Weave script.
%dw 2.0
output application/java
fun parseSchema(schema) =
schema map ( item , index ) -> {
fieldName : item.FieldName,
fieldType : item.FieldType,
fieldDescription : item.fieldDescription,
fieldMode : item.fieldMode
}
---
parseSchema(payload)
- Add Set Payload to the canvas and set below JSON as value. This JSON contains value for fields in Table Schema and RowId to specify row index of the data.
[
{
"RowId": "1",
"Name": "AAAAAA",
"EmployeeId" : "1234",
"Age" : 25,
"ContactNumber" : "11111111111",
"Designation" : "SE",
"Salary": 500000
},
{
"RowId": "2",
"Name": "BBBBBBB",
"EmployeeId" : "2345",
"Age" : 22,
"ContactNumber" : "222222222",
"Designation" : "SSE",
"Salary": 1000000
},
{
"RowId": "3",
"Name": "CCCCCCCC",
"EmployeeId" : "3456",
"Age" : 29,
"ContactNumber" : "3333333333",
"Designation" : "LEAD",
"Salary": 1500000
},
{
"RowId": "4",
"Name": "DDDDDDD",
"EmployeeId" : "4567",
"Age" : 27,
"ContactNumber" : "444444444",
"Designation" : "MANAGER",
"Salary": 1900000
}
]
- Add Transform Message to the canvas and add below DataWeave script. It transforms JSON Payload to Row Data in Insert All operation. The output of transform message is used to insert data into table.
%dw 2.0
output application/java
---
payload map (( payload01 , indexOfPayload01 ) -> {
Name: payload01.Name,
EmployeeId: payload01.EmployeeId,
Age: payload01.Age,
ContactNumber: payload01.ContactNumber,
Designation: payload01.Designation,
Salary: payload01.Salary,
RowID: payload01.RowId
})
-
Search InsertAll, drag it onto the canvas. Provide Dataset Name , Table Name.
-
Set payload of Transform Message as expression to Rows data or set above DataWeave script into Rows data as expression.
-
Drag the Logger onto the canvas and log payload as expression to log the output of the operation.
-
Drag Flow Reference and provide flow name of the next sub flow
extractJobFlow. -
Now create a new sub flow
extractJobFlow. Drag Create Job onto the canvas and select Extract Job as job config. -
Provide Destination URIs (URI of Google Cloud Storage where you want to extract Google BigQuery’s table data).
-
Provide Source Table and Dataset
-
Note: For Extract Job operation, Only simple types may be exported as CSV.
-
Add Set Variable and set variable name as JobId and below value as expression
%dw 2.0
output application/java
---
payload.jobId.job
-
This JobId variable can be used by other operations to get the details of the Job. In this use case, it is used by Get Job operation.
-
Drag Flow Reference and provide flow name of next sub flow
checkJobStatusFlow. -
Create a new sub flow
checkJobStatusFlow, search for Get Job drag it onto the canvas and provide jobName as expressionvars.jobId -
Drag Set Variable and set variable name as jobStatus and below value as expression
%dw 2.0
output application/java
---
payload.status.state
-
This jobStatus variable can be used to check the status of the Job.
-
Add Choice from Mule Palette to the canvas. It is used to switch between the different choices depending on provided expression.
-
Add below condition as expression in Choice to check if the job has completed it’s execution.
vars.jobStatus == 'DONE'
-
To the expression/when side, add Logger to log jobStatus and add FLow Reference to call another sub flow deleteFlow to delete the resources.
-
To the default side of the Choice, again add the Logger to log jobStatus as expression
vars.jobStatus. -
As Job is still Running, add Flow Reference to call same flow
checkJobStatusFlowagain. -
Create new sub flow deleteFlow to delete the resources.
-
Drag Delete Table and provide table, dataset name.
-
Drag Delete Dataset and provide dataset name.
-
After you create the flow, right-click the project and click Run As > Mule Applciation
-
Once application is deployed, use HTTP Listener’s Path to execute the Mule Flow.
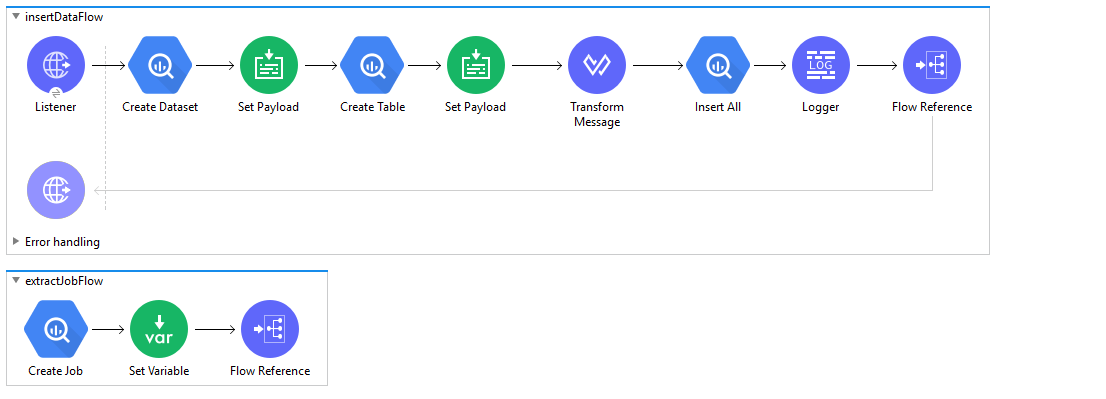
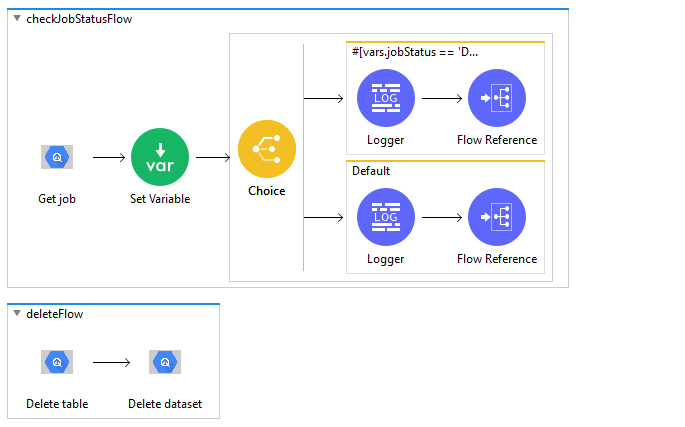
Example Use Case Code :
Paste this XML code into Anypoint Studio to experiment with the flow described above.
<?xml version="1.0" encoding="UTF-8"?>
<mule xmlns:ee="http://www.mulesoft.org/schema/mule/ee/core"
xmlns:file="http://www.mulesoft.org/schema/mule/file"
xmlns:bigquery="http://www.mulesoft.org/schema/mule/bigquery"
xmlns:http="http://www.mulesoft.org/schema/mule/http"
xmlns="http://www.mulesoft.org/schema/mule/core"
xmlns:doc="http://www.mulesoft.org/schema/mule/documentation" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.mulesoft.org/schema/mule/core http://www.mulesoft.org/schema/mule/core/current/mule.xsd
http://www.mulesoft.org/schema/mule/http http://www.mulesoft.org/schema/mule/http/current/mule-http.xsd
http://www.mulesoft.org/schema/mule/bigquery http://www.mulesoft.org/schema/mule/bigquery/current/mule-bigquery.xsd
http://www.mulesoft.org/schema/mule/file http://www.mulesoft.org/schema/mule/file/current/mule-file.xsd
http://www.mulesoft.org/schema/mule/ee/core http://www.mulesoft.org/schema/mule/ee/core/current/mule-ee.xsd">
<configuration-properties file="mule-application.properties" />
<http:listener-config name="HTTP_Listener_config" doc:name="HTTP Listener config" doc:id="dfd19971-8787-4989-a415-96de3ce3f63b" >
<http:listener-connection host="0.0.0.0" port="8081" />
</http:listener-config>
<bigquery:config name="Google_BigQuery_Config" doc:name="Google BigQuery Config" doc:id="12ffd8ec-da1b-4407-ac47-62f43ab5c2d9" >
<bigquery:connection projectId="${bigquery.projectId}" jsonServiceAccountKeyFile="${bigquery.jsonServiceAccountKeyFile}" />
</bigquery:config>
<flow name="insertDataFlow" doc:id="a8e4334f-5902-49d5-b599-976d0026c631" >
<http:listener doc:name="Listener" doc:id="20fbe3d6-ee57-4710-aa19-bee843b10e83" config-ref="HTTP_Listener_config" path="/extractData"/>
<bigquery:create-dataset doc:name="Create Dataset" doc:id="96e19df9-b9cc-4442-b690-14ead03360e7" config-ref="Google_BigQuery_Config" datasetName="${bigquery.dataset}"/>
<set-payload value='#[[{
"FieldName" : "Name",
"FieldType" : "STRING",
"fieldDescription" : "This is name",
"fieldMode" : "NULLABLE"
},
{
"FieldName" : "EmployeeID",
"FieldType" : "STRING",
"fieldDescription" : "This is Employee Id",
"fieldMode" : "NULLABLE"
},
{
"FieldName" : "Age",
"FieldType" : "INTEGER",
"fieldDescription" : "This is Age",
"fieldMode" : "NULLABLE"
},
{
"FieldName" : "ContactNumber",
"FieldType" : "STRING",
"fieldDescription" : "This is Contact Number",
"fieldMode" : "NULLABLE"
},
{
"FieldName" : "Designation",
"FieldType" : "STRING",
"fieldDescription" : "This is Designation",
"fieldMode" : "NULLABLE"
},
{
"FieldName" : "Salary",
"FieldType" : "FLOAT",
"fieldDescription" : "This is Salary",
"fieldMode" : "NULLABLE"
}
]]' doc:name="Set Payload" doc:id="a95006b5-ee37-4a57-9e22-1f2f3b56bf8c" />
<bigquery:create-table doc:name="Create Table" doc:id="8e42b1a6-7f68-4036-bba0-0a5a4972252d" config-ref="Google_BigQuery_Config" tableFields="#[%dw 2.0
output application/java
fun parseSchema(schema) =
schema map ( item , index ) -> {
fieldName : item.FieldName,
fieldType : item.FieldType,
fieldDescription : item.fieldDescription,
fieldMode : item.fieldMode
}
---
parseSchema(payload)]">
<bigquery:table-info>
<bigquery:table table="${bigquery.table}" dataset="${bigquery.dataset}" />
</bigquery:table-info>
</bigquery:create-table>
<set-payload value='#[[
{
"RowId": "1",
"Name": "AAAAAA",
"EmployeeId" : "1234",
"Age" : 25,
"ContactNumber" : "11111111111",
"Designation" : "SE",
"Salary": 500000
},
{
"RowId": "2",
"Name": "BBBBBBB",
"EmployeeId" : "2345",
"Age" : 22,
"ContactNumber" : "222222222",
"Designation" : "SSE",
"Salary": 1000000
},
{
"RowId": "3",
"Name": "CCCCCCCC",
"EmployeeId" : "3456",
"Age" : 29,
"ContactNumber" : "3333333333",
"Designation" : "LEAD",
"Salary": 1500000
},
{
"RowId": "4",
"Name": "DDDDDDD",
"EmployeeId" : "4567",
"Age" : 27,
"ContactNumber" : "444444444",
"Designation" : "MANAGER",
"Salary": 1900000
}
]]' doc:name="Set Payload" doc:id="8dfb06ae-e326-4bba-8f79-c72fc9c37b65"/>
<ee:transform doc:name="Transform Message" doc:id="54c6b703-49c9-48b3-8808-06eb4592aa26" >
<ee:message >
<ee:set-payload ><![CDATA[%dw 2.0
output application/java
---
payload map (( payload01 , indexOfPayload01 ) -> {
Name: payload01.Name,
EmployeeId: payload01.EmployeeId,
Age: payload01.Age,
ContactNumber: payload01.ContactNumber,
Designation: payload01.Designation,
Salary: payload01.Salary,
RowID: payload01.RowId
})]]></ee:set-payload>
</ee:message>
</ee:transform>
<bigquery:insert-all doc:name="Insert All" doc:id="ffbc7102-fc39-4145-ab8d-c9922fe53fee" config-ref="Google_BigQuery_Config" rowsData="#[payload]" tableId="${bigquery.table}" datasetId="${bigquery.dataset}">
</bigquery:insert-all>
<logger level="INFO" doc:name="Logger" doc:id="0fc1f6ca-d002-414d-9d58-7e41cb05837a" message="#[payload]"/>
<flow-ref doc:name="Flow Reference" doc:id="8bc003f2-ebe0-4462-a565-3e9dc73b0794" name="extractJobFlow"/>
</flow>
<sub-flow name="extractJobFlow" doc:id="be8d2791-bf80-4f85-a5a3-d23a6db1513c" >
<bigquery:create-job doc:name="Create Job" doc:id="2c10a3ed-b2ee-4095-a7ee-2ef40cc65a7b" config-ref="Google_BigQuery_Config">
<bigquery:job-config>
<bigquery:job-configuration>
<bigquery:extract-job>
<bigquery:destination-uris >
<bigquery:destination-uri value="${bigquery.extractJob.destinationUri}" />
</bigquery:destination-uris>
<bigquery:source-table table="${bigquery.table}" dataset="${bigquery.dataset}" />
</bigquery:extract-job>
</bigquery:job-configuration>
</bigquery:job-config>
<bigquery:job-info />
</bigquery:create-job>
<set-variable value="#[%dw 2.0
output application/java
---
payload.jobId.job]" doc:name="Set Variable" doc:id="fdc88411-56ec-412e-91f1-ba4c87551650" variableName="jobId"/>
<flow-ref doc:name="Flow Reference" doc:id="fb40cb20-9080-4bcf-938c-8c63357bb88d" name="checkJobStatusFlow"/>
</sub-flow>
<sub-flow name="checkJobStatusFlow" doc:id="8a644e58-6d70-48ea-ace8-f72428d3720b" >
<bigquery:get-job doc:name="Get job" doc:id="80cb077c-b553-4da6-b849-6d1c09f7d855" config-ref="Google_BigQuery_Config" jobName="#[vars.jobId]"/>
<set-variable value="#[%dw 2.0
output application/java
---
payload.status.state]" doc:name="Set Variable" doc:id="b7789d0e-77e9-4638-be3d-1411e09ee997" variableName="jobStatus"/>
<choice doc:name="Choice" doc:id="8e302a4e-07e5-43b5-b1df-ab357645632f" >
<when doc:id="5272c64a-db96-4550-a816-684ce45aed2c" expression="#[vars.jobStatus == 'DONE']">
<logger level="INFO" doc:name="Logger" doc:id="2653f90b-cc1f-4aa0-bc15-7e2cab6ebee1" message="#[vars.jobStatus]"/>
<flow-ref doc:name="Flow Reference" doc:id="8ff94cb8-3fbb-40f7-af6c-3465d3424b22" name="deleteFlow"/>
</when>
<otherwise >
<logger level="INFO" doc:name="Logger" doc:id="08b88306-7fbc-4bfd-b47a-52d97b5ed1af" message="#[vars.jobStatus]"/>
<flow-ref doc:name="Flow Reference" doc:id="6f588215-c941-4581-bd23-8f90fa3c736e" name="checkJobStatusFlow"/>
</otherwise>
</choice>
</sub-flow>
<sub-flow name="deleteFlow" doc:id="6b9030d8-5418-4927-9a88-adb8ae0bf31e" >
<bigquery:delete-table doc:name="Delete table" doc:id="a0430097-0fe3-4c20-b1db-fc4289693b1f" config-ref="Google_BigQuery_Config">
<bigquery:table table="${bigquery.table}" dataset="${bigquery.dataset}" />
</bigquery:delete-table>
<bigquery:delete-dataset doc:name="Delete dataset" doc:id="3f4f5910-3acd-4c5e-9cc8-670e05a6b6e8" config-ref="Google_BigQuery_Config" datasetId="${bigquery.dataset}"/>
</sub-flow>
</mule>
Load Data to BigQuery Table from Google Cloud and Perform Query
This use case demonstrates Loading data from Google Cloud Storage and Query table. It creates dataset and load data from Google Cloud Storage to BigQuery table. It also get the details of the load job and check job execution status. Lastly, It executes Query Job to fetch the loaded records once load job complete execution.
-
In Anypoint Studio, click File > New > Mule Project, name the project, and click Finish.
-
In the search field, type Http and drag the HTTP Listener to the canvas.
-
Click the HTTP Listener, click the green plus sign to the right of Connector Configuration. On the next screen, add the host as well as port, click OK
-
Provide Path to HTTP Listener (Example: /loadData)
-
On the Mule Palette, search for Create Dataset and drag it onto the canvas. Provide Dataset Name and other details.
-
Add Create Job in the canvas. Select Load Job in Job Configurations.
-
Provide Source Uris (URI of Google Cloud Storage from where you want to load data) and Destination table and dataset name.
-
Once Load Job is executed, below table schema is created at destination.
| Field name | Field type |
|---|---|
| Section_Name | String |
| Menu_Name | String |
| Channel_ID | Integer |
| Editor_User_Name_ | String |
-
Data is also loaded into destination table from source URI.
-
Add Set Variable in the canvas and set variable name as JobId and below value as expression
%dw 2.0
output application/java
---
payload.jobId.job
-
This JobId variable can be used by other operations to get the details of the Job. In this use case, it is used by Get Job operation.
-
Add Flow Reference to the canvas. Provide flow name
queryDataFlowwhich performs query on table once Load Job completes its execution and accordingly create sub flowqueryDataFlow. -
Add Delete Table into the existing flow and provide table name and dataset name.
-
Add Delete Dataset in the canvas and provide dataset name. These operations will delete the resources.
-
Now create a new sub flow
queryDataFlow. Add Get Job in the canvas of the sub flow. -
Provide Job Name as expression
vars.jobIDto get the information of the specified Job using variable jobId. -
Add Set Variable in the canvas and set variable name as jobStatus and below value as expression:
%dw 2.0
output application/java
---
payload.status.state
-
This jobStatus variable can be used to check the status of the Job.
-
Add Choice to the canvas. It is used to switch between the different choices depending on provided expression.
-
Add below condition as expression in Choice to check if the job has completed it’s execution.
vars.jobStatus == 'DONE'
-
To the expression/when side, add Query to the canvas. This Query is synchronous operation. That’s why it returns the query result (Java object of com.mulesoft.connectors.bigquery.api.TableResult) as output.
-
Note: Don’t transform output of Query operation (Java object of com.mulesoft.connectors.bigquery.api.TableResult) directly into JSON because it is complex object and we cannot convert it into JSON directly. If required, transform specific fields of TableResult object into JSON.
-
Provide Query String to query on the table created earlier by Load Job operation. Also provide other fields.
-
Query operation returns result as Java Object. To transform result to JSON, add Transform Message to the canvas.
-
Now add below DataWeave script. It transforms com.mulesoft.connectors.bigquery.api.TableResult Java object to JSON.
%dw 2.0
output application/json
var schema=payload.schema.fields
---
payload.values map ((value, index) -> {
(schema[0].name): value[0].value,
(schema[1].name): value[1].value,
(schema[2].name): value[2].value,
(schema[3].name): value[3].value,
})
-
This transform message returns query result in JSON format.
-
Add Logger to the canvas to log transformed json result of the query:
output application/json
---
payload
-
To the default side of the Choice, again add the Logger to log jobStatus as expression
vars.jobStatus. -
As Job is still Running, add Flow Reference to call same flow
queryDataFlowagain. -
After creating the flow, right-click the project and click Run As > Mule Applciation
-
Once application is deployed, use HTTP Listener’s Path to execute the Mule Flow.
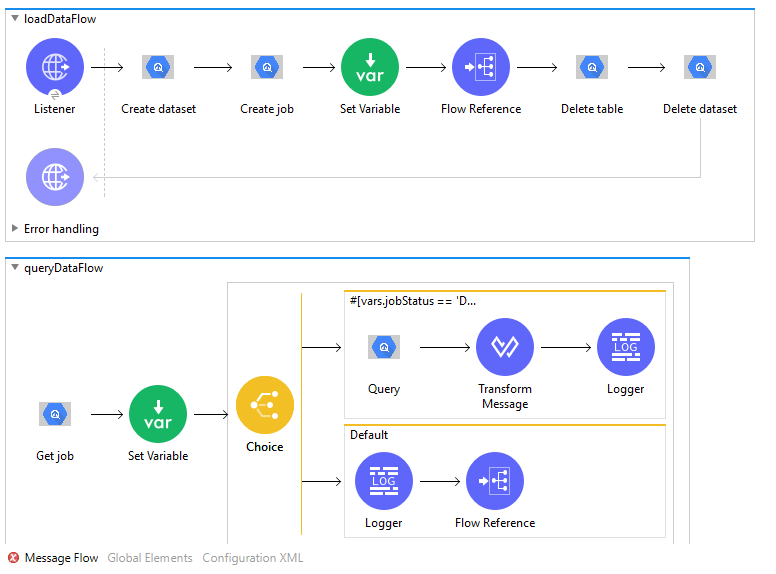
Example Use Case Code :
Paste this XML code into Anypoint Studio to experiment with the flow described in the previous section.
<?xml version="1.0" encoding="UTF-8"?>
<mule xmlns:ee="http://www.mulesoft.org/schema/mule/ee/core"
xmlns:bigquery="http://www.mulesoft.org/schema/mule/bigquery"
xmlns:http="http://www.mulesoft.org/schema/mule/http"
xmlns="http://www.mulesoft.org/schema/mule/core"
xmlns:doc="http://www.mulesoft.org/schema/mule/documentation"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.mulesoft.org/schema/mule/core http://www.mulesoft.org/schema/mule/core/current/mule.xsd
http://www.mulesoft.org/schema/mule/http http://www.mulesoft.org/schema/mule/http/current/mule-http.xsd
http://www.mulesoft.org/schema/mule/bigquery http://www.mulesoft.org/schema/mule/bigquery/current/mule-bigquery.xsd
http://www.mulesoft.org/schema/mule/ee/core http://www.mulesoft.org/schema/mule/ee/core/current/mule-ee.xsd">
<configuration-properties file="mule-application.properties" />
<http:listener-config name="HTTP_Listener_config" doc:name="HTTP Listener config" doc:id="9a56d0bc-6284-4a37-8828-80da4587a7ba" >
<http:listener-connection host="0.0.0.0" port="8081" />
</http:listener-config>
<bigquery:config name="Google_BigQuery_Config" doc:name="Google BigQuery Config" doc:id="fad958a1-e62f-47ad-91d5-ca4942c0a31b" >
<bigquery:connection projectId="${bigquery.projectId}" jsonServiceAccountKeyFile="${bigquery.jsonServiceAccountKeyFile}" />
</bigquery:config>
<http:request-config name="HTTP_Request_configuration" doc:name="HTTP Request configuration" doc:id="54dad089-58e8-49ab-a484-ca56a0c4a114" >
<http:request-connection host="localhost" port="9000">
</http:request-connection>
</http:request-config>
<flow name="loadDataFlow" doc:id="374138e6-4904-4bc7-a4ff-560014ee33c7" >
<http:listener doc:name="Listener" doc:id="c3e4c3e2-8427-410c-9cfb-917523724b2f" path="${bigquery.httpListener.path}" config-ref="HTTP_Listener_config"/>
<bigquery:create-dataset doc:name="Create dataset" doc:id="e2fadc2a-834f-42cb-85d6-07c1319f1c19" datasetName="${bigquery.dataset}" config-ref="Google_BigQuery_Config"/>
<bigquery:create-job doc:name="Create job" doc:id="68829ec2-8067-4995-a8c9-af11c1d127c1" config-ref="Google_BigQuery_Config">
<bigquery:job-config >
<bigquery:job-configuration>
<bigquery:load-job formatOption="${bigquery.loadJob.formatOption}">
<bigquery:source-uris >
<bigquery:source-uri value="${bigquery.loadJob.sourceUri}" />
</bigquery:source-uris>
<bigquery:destination-table table="${bigquery.table}" dataset="${bigquery.dataset}" />
</bigquery:load-job>
</bigquery:job-configuration>
</bigquery:job-config>
<bigquery:job-info />
</bigquery:create-job>
<set-variable value="#[%dw 2.0
output application/java
---
payload.jobId.job]" doc:name="Set Variable" doc:id="c57e87e8-bd90-43f7-83c5-fe0a610c9617" variableName="jobID"/>
<flow-ref doc:name="Flow Reference" doc:id="ebb32e18-09c2-4839-bf99-2817a0d3b1d7" name="queryDataFlow"/>
<bigquery:delete-table doc:name="Delete table" doc:id="4d69ab27-251c-479e-8f5b-6fb6d9cb0265" config-ref="Google_BigQuery_Config">
<bigquery:table table="${bigquery.table}" dataset="${bigquery.dataset}" />
</bigquery:delete-table>
<bigquery:delete-dataset doc:name="Delete dataset" doc:id="b39caf65-a113-40a6-aac0-b6f61cffc17b" config-ref="Google_BigQuery_Config" datasetId="${bigquery.dataset}"/>
</flow>
<sub-flow name="queryDataFlow" doc:id="3167d5b2-9abb-41a3-a74a-49e1e9c60ad6" >
<bigquery:get-job doc:name="Get job" doc:id="f44a81db-122b-4e0b-9abf-edacf227ffb5" config-ref="Google_BigQuery_Config" jobName="#[vars.jobId]"/>
<set-variable value="#[%dw 2.0
output application/java
---
payload.status.state]" doc:name="Set Variable" doc:id="e829c637-3825-4774-ae8c-1d2af39801e8" variableName="jobStatus"/>
<choice doc:name="Choice" doc:id="f78793df-3565-4e52-af50-07598811b37c" >
<when doc:id="899037f1-ccdb-4661-aae9-26f0d036b668" expression="#[vars.jobStatus == 'DONE']">
<bigquery:query doc:name="Query" doc:id="859d3696-813a-48ca-a460-c2c8ada114ed" config-ref="Google_BigQuery_Config">
<bigquery:query-job>
<bigquery:query-string>SELECT * FROM `${bigquery.projectId}.${bigquery.dataset}.${bigquery.table}` WHERE Channel_ID=3711 AND Editor__User_Name_='scraig'</bigquery:query-string>
</bigquery:query-job>
<bigquery:job-info-options />
</bigquery:query>
<ee:transform doc:name="Transform Message" doc:id="6009fb8a-9c6f-4a41-ab3e-79a114707211" >
<ee:message >
<ee:set-payload ><![CDATA[%dw 2.0
output application/json
var schema=payload.schema.fields
---
payload.values map ((value, index) -> {
(schema[0].name): value[0].value,
(schema[1].name): value[1].value,
(schema[2].name): value[2].value,
(schema[3].name): value[3].value,
})]]></ee:set-payload>
</ee:message>
</ee:transform>
<logger level="INFO" doc:name="Logger" doc:id="2eb21829-1b9d-4891-909e-2b183654e4e0" message="#[output application/json
---
payload]" />
</when>
<otherwise >
<logger level="INFO" doc:name="Logger" doc:id="74b1156a-82a6-4f5e-a3ff-84ddc5161949" message="#[vars.jobStatus]"/>
<flow-ref doc:name="Flow Reference" doc:id="56f7507b-ed74-4c1e-997b-e89de658ef09" name="queryDataFlow"/>
</otherwise>
</choice>
</sub-flow>
</mule>
Insert Data to BigQuery Table, Perform Asynchronous Query and Get Query Result
This use case demonstrates Inserting data into BigQuery Table, query table asynchronously and get query result once query job completes execution. It creates dataset and table, Insert data into it, executes asynchronous query job to fetch the loaded records. Once job status is DONE, get the query result. Atlast, it deletes dataset and table.
-
In Anypoint Studio, click File > New > Mule Project, name the project, and click Finish.
-
In the search field, type Http and drag the HTTP Listener to the canvas.
-
Click the HTTP Listener, click the green plus sign to the right of Connector Configuration. On the next screen, add the host and port, click OK.
-
Provide Path to HTTP Listener (Example: /asyncQueryData)
-
On the Mule Palette, search for Create Dataset and drag it onto the canvas.
-
Provide appropriate dataset name and other fields.
-
Add Set Payload onto the canvas. Set below JSON for table fields/schema as expression to the payload value.
[{
"FieldName" : "Name",
"FieldType" : "STRING",
"fieldDescription" : "this is name",
"fieldMode" : "NULLABLE"
},
{
"FieldName" : "EmployeeID",
"FieldType" : "STRING",
"fieldDescription" : "this is employeeId",
"fieldMode" : "NULLABLE"
},
{
"FieldName" : "ContactDetails",
"FieldType" : "RECORD",
"fieldDescription" : "this is contact details",
"fieldMode" : "NULLABLE",
"subFields" : [{
"FieldName" : "Address",
"FieldType" : "RECORD",
"fieldDescription" : "this is address",
"fieldMode" : "NULLABLE",
"subFields" : [{
"FieldName" : "City",
"FieldType" : "STRING",
"fieldDescription" : "this is city",
"fieldMode" : "NULLABLE"
},
{
"FieldName" : "State",
"FieldType" : "STRING",
"fieldDescription" : "this is state",
"fieldMode" : "NULLABLE"
},
{
"FieldName" : "Country",
"FieldType" : "STRING",
"fieldDescription" : "this is country",
"fieldMode" : "NULLABLE"
}]
},
{
"FieldName" : "ContactNumber",
"FieldType" : "RECORD",
"fieldDescription" : "this is contact number",
"fieldMode" : "NULLABLE",
"subFields" : [{
"FieldName" : "CountryCode",
"FieldType" : "STRING",
"fieldDescription" : "this is CountryCode",
"fieldMode" : "NULLABLE"
},
{
"FieldName" : "MobileNumber",
"FieldType" : "INTEGER",
"fieldDescription" : "this is MobileNumber",
"fieldMode" : "NULLABLE"
}]
}]
}]
- We used following Table Schema:
| Field name | Field type |
|---|---|
| Name | String |
| EmployeeID | String |
| ContactDetails | Record |
| ContactDetails.Address | Record |
| ContactDetails.Address.City | String |
| ContactDetails.Address.State | String |
| ContactDetails.Address.Country | String |
| ContactDetails.ContactNumber | Record |
| ContactDetails.ContactNumber.CountryCode | String |
| ContactDetails.ContactNumber.MobileNumber | Integer |
- Add Create Table onto the canvas. Provide Dataset Name, Table Name and map payload to the Table Fields using below Data Weave script.
%dw 2.0
output application/java
fun parseSchema(schema) =
schema map ( payload01 , indexOfPayload01 ) -> {
fieldName : payload01.FieldName,
fieldType : payload01.FieldType,
fieldDescription : payload01.fieldDescription,
fieldMode : payload01.fieldMode,
fieldSubFields : parseSchema(payload01.subFields)
}
---
parseSchema(payload)
- Add Set Payload to the canvas and set below JSON as value. This JSON contains value for fields in Table Schema and RowId to specify row index of the data.
[
{
"RowId": "1",
"Name": "AAA",
"EmployeeId" : "264",
"ContactDetails":{
"Address":{
"City": "Pune",
"State":"MH",
"Country":"India"
},
"ContactNumber":{
"CountryCode":"+91",
"MobileNumber":11111111
}
}
},
{
"RowId": "2",
"Name": "BBB",
"EmployeeId" : "544",
"ContactDetails":{
"Address":{
"City": "Mumbai",
"State":"MH",
"Country":"India"
},
"ContactNumber":{
"CountryCode":"+1",
"MobileNumber":2222222
}
}
},
{
"RowId": "3",
"Name": "CCC",
"EmployeeId" : "2342",
"ContactDetails":{
"Address":{
"City": "Vadodara",
"State":"GJ",
"Country":"India"
},
"ContactNumber":{
"CountryCode":"+91",
"MobileNumber":333333333
}
}
},
{
"RowId": "4",
"Name": "DDD",
"EmployeeId" : "09823",
"ContactDetails":{
"Address":{
"City": "Jaipur",
"State":"RJ",
"Country":"India"
},
"ContactNumber":{
"CountryCode":"+1",
"MobileNumber":44444444
}
}
}
]
- Add Transform Message to the canvas and add below DataWeave script. It transforms JSON Payload to Row Data in Insert All operation. The output of transform message is used to insert data into table.
%dw 2.0
output application/java
---
payload map (( payload01 , indexOfPayload01 ) -> {
Name: payload01.Name,
EmployeeId: payload01.EmployeeId,
ContactDetails: {
Address: {
City: payload01.ContactDetails.Address.City,
State: payload01.ContactDetails.Address.State,
Country: payload01.ContactDetails.Address.Country
},
ContactNumber: {
CountryCode: payload01.ContactDetails.ContactNumber.CountryCode,
MobileNumber: payload01.ContactDetails.ContactNumber.MobileNumber
}
},
RowID: payload01.RowId
})
-
Search InsertAll, drag it onto the canvas. Provide Dataset Name , Table Name.
-
Set payload of Transform Message as expression to Rows data or set above DataWeave script into Rows data as expression.
-
Drag the Logger onto the canvas and log payload as expression to log the output of the operation.
-
Drag Flow Reference and provide flow name of the next sub flow
asynchronousQueryDataSubFlow. -
Now create a new sub flow
asynchronousQueryDataSubFlow. Add Create Job in the canvas and select Query Job as job configuration. -
This Create Job → Query Job is asynchronous operation and it returns Job details as com.mulesoft.connectors.bigquery.api.job.Job object. To get the result of this query job, use Get Query Result after job completion with JobId of this Query Job.
-
Provide Query String to query on the table and other fields.
-
Example -
SELECT * FROM <ProjectID.DatasetName.TableName> WHERE ContactDetails.Address.State in UNNEST (@param). Here, @param is Named Query Parameter. -
To create Named Query Parameter, check Named Query Parameters and provide the key and value as expression. Here, key is param and value is Array of String.
-
Note - While using query parameter for array in the query string, please use UNNEST in the query.
-
This Create Job → Query Job returns Job details. Hence, save Job ID in a variable to execute further operations.
-
Add Set Variable and set variable name as JobId and below value as expression
%dw 2.0
output application/java
---
payload.jobId.job
-
This JobId variable can be used by other operations to get the details of the Job. In this use case, it is used by Get Job operation.
-
Drag Flow Reference and provide flow name of next sub flow
checkJobStatusAndQuerySubFlow. -
Create a new sub flow
checkJobStatusAndQuerySubFlow, add Get Job in the canvas and provide jobName as expressionvars.jobId -
Add Set Variable and set variable name as jobStatus and below value as expression
%dw 2.0
output application/java
---
payload.status.state
-
This jobStatus variable can be used to check the status of the Job.
-
Add Choice from Mule Palette to the canvas. It is used to switch between the different choices depending on provided expression.
-
Add below condition as expression in Choice to check if the job has completed it’s execution.
vars.jobStatus == 'DONE'
-
To the expression/when side, add Logger to log jobStatus as expression
vars.jobStatus. -
Add Get Query Result in the canvas to get the result of the Create Job → Query Job operation based on jobId.
-
Provide Job name as expresion
vars.jobId -
Get Query Result returns query result as Java Object. To transform returned com.mulesoft.connectors.bigquery.api.TableResult Java Object to JSON, add Transform Message to the canvas.
-
Now add below DataWeave script. It transforms com.mulesoft.connectors.bigquery.api.TableResult Java object to JSON.
%dw 2.0
output application/json
var schema=payload.schema.fields
---
payload.values map ((row, index) -> {
(schema[0].name): row[0].stringValue,
(schema[1].name): row[1].stringValue,
(schema[2].name): {
(schema[2].subFields[0].name): {
(schema[2].subFields[0].subFields[0].name): row[2].value[0].value[0].stringValue,
(schema[2].subFields[0].subFields[1].name): row[2].value[0].value[1].stringValue,
(schema[2].subFields[0].subFields[2].name): row[2].value[0].value[2].stringValue
},
(schema[2].subFields[1].name): {
(schema[2].subFields[1].subFields[0].name): row[2].value[1].value[0].stringValue,
(schema[2].subFields[1].subFields[1].name): row[2].value[1].value[1].stringValue
}
}
})
-
This transform message returns query result in JSON format.
-
Add Logger in the canvas to log transformed json result of the query:
output application/json
---
payload
-
Atlast, to delete the resources, add Delete Table in the canvas and provide table name and dataset name.
-
Add Delete Dataset in the canvas and provide dataset name.
-
To the default side of the Choice, again add the Logger to log jobStatus as expression
vars.jobStatus. -
As Job is still Running, add Flow Reference to call same flow
checkJobStatusAndQuerySubFlowagain. -
After you create the flow, right-click the project and click Run As > Mule Applciation
-
Once application is deployed, use HTTP Listener’s Path to execute the Mule Flow.
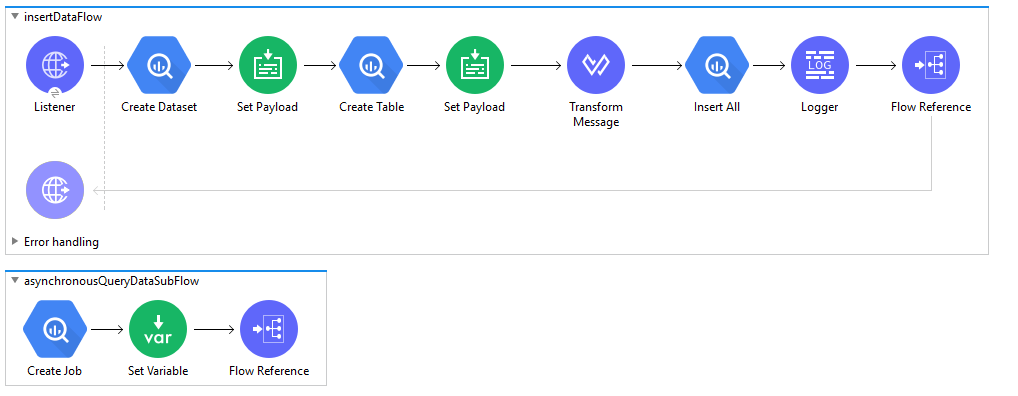
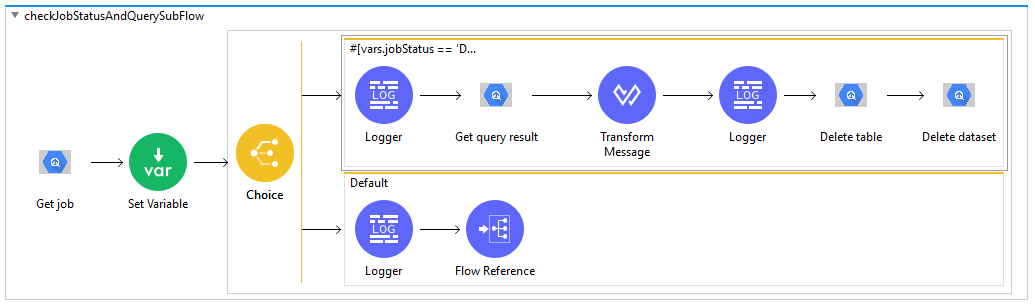
Example Use Case Code :
Paste this XML code into Anypoint Studio to experiment with the flow described above.
<?xml version="1.0" encoding="UTF-8"?>
<mule xmlns:ee="http://www.mulesoft.org/schema/mule/ee/core"
xmlns:http="http://www.mulesoft.org/schema/mule/http" xmlns:bigquery="http://www.mulesoft.org/schema/mule/bigquery"
xmlns="http://www.mulesoft.org/schema/mule/core"
xmlns:doc="http://www.mulesoft.org/schema/mule/documentation" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="
http://www.mulesoft.org/schema/mule/ee/core http://www.mulesoft.org/schema/mule/ee/core/current/mule-ee.xsd http://www.mulesoft.org/schema/mule/core http://www.mulesoft.org/schema/mule/core/current/mule.xsd
http://www.mulesoft.org/schema/mule/bigquery http://www.mulesoft.org/schema/mule/bigquery/current/mule-bigquery.xsd
http://www.mulesoft.org/schema/mule/http http://www.mulesoft.org/schema/mule/http/current/mule-http.xsd">
<configuration-properties file="mule-application.properties" />
<bigquery:config name="Google_BigQuery_Config" doc:name="Google BigQuery Config" doc:id="3533061e-e19f-4a0a-a0c5-9d6721bc6e96" >
<bigquery:connection projectId="${bigquery.projectId}" jsonServiceAccountKeyFile="${bigquery.jsonServiceAccountKeyFile}"/>
</bigquery:config>
<http:listener-config name="HTTP_Listener_config" doc:name="HTTP Listener config" doc:id="fd11a444-404a-4ef5-afee-8b917cb8a286" >
<http:listener-connection host="0.0.0.0" port="8081" />
</http:listener-config>
<flow name="insertDataFlow" doc:id="434da132-4106-4fdc-aee0-301136274032" >
<http:listener doc:name="Listener" doc:id="1da141b3-834f-4c92-9e7a-8f27bbf43246" config-ref="HTTP_Listener_config" path="${bigquery.httpListener.path}"/>
<bigquery:create-dataset doc:name="Create Dataset" doc:id="1046e0f1-a885-4154-9c27-e9550ce8a31a" config-ref="Google_BigQuery_Config" datasetName="${bigquery.dataset}"/>
<set-payload doc:name="Set Payload" doc:id="ead5e87c-9dff-4404-9f0d-19ddd28d686a" value='#[[{
"FieldName" : "Name",
"FieldType" : "STRING",
"fieldDescription" : "this is name",
"fieldMode" : "NULLABLE"
},
{
"FieldName" : "EmployeeID",
"FieldType" : "STRING",
"fieldDescription" : "this is employeeId",
"fieldMode" : "NULLABLE"
},
{
"FieldName" : "ContactDetails",
"FieldType" : "RECORD",
"fieldDescription" : "this is contact details",
"fieldMode" : "NULLABLE",
"subFields" : [{
"FieldName" : "Address",
"FieldType" : "RECORD",
"fieldDescription" : "this is address",
"fieldMode" : "NULLABLE",
"subFields" : [{
"FieldName" : "City",
"FieldType" : "STRING",
"fieldDescription" : "this is city",
"fieldMode" : "NULLABLE"
},
{
"FieldName" : "State",
"FieldType" : "STRING",
"fieldDescription" : "this is state",
"fieldMode" : "NULLABLE"
},
{
"FieldName" : "Country",
"FieldType" : "STRING",
"fieldDescription" : "this is country",
"fieldMode" : "NULLABLE"
}]
},
{
"FieldName" : "ContactNumber",
"FieldType" : "RECORD",
"fieldDescription" : "this is contact number",
"fieldMode" : "NULLABLE",
"subFields" : [{
"FieldName" : "CountryCode",
"FieldType" : "STRING",
"fieldDescription" : "this is CountryCode",
"fieldMode" : "NULLABLE"
},
{
"FieldName" : "MobileNumber",
"FieldType" : "INTEGER",
"fieldDescription" : "this is MobileNumber",
"fieldMode" : "NULLABLE"
}]
}]
}
]]'/>
<bigquery:create-table doc:name="Create Table" doc:id="00af2b19-f757-4382-b5fa-e7a418d9bde3" config-ref="Google_BigQuery_Config" tableFields='#[%dw 2.0
output application/java
fun parseSchema(schema) =
schema map ( payload01 , indexOfPayload01 ) -> {
fieldName : payload01.FieldName,
fieldType : payload01.FieldType,
fieldDescription : payload01.fieldDescription,
fieldMode : payload01.fieldMode,
fieldSubFields : parseSchema(payload01.subFields)
}
---
parseSchema(payload)]'>
<bigquery:table-info>
<bigquery:table table="${bigquery.table}" dataset="${bigquery.dataset}" />
</bigquery:table-info>
</bigquery:create-table>
<set-payload value='#[[
{
"RowId": "1",
"Name": "AAA",
"EmployeeId" : "264",
"ContactDetails":{
"Address":{
"City": "Pune",
"State":"MH",
"Country":"India"
},
"ContactNumber":{
"CountryCode":"+91",
"MobileNumber":11111111
}
}
},
{
"RowId": "2",
"Name": "BBB",
"EmployeeId" : "544",
"ContactDetails":{
"Address":{
"City": "Mumbai",
"State":"MH",
"Country":"India"
},
"ContactNumber":{
"CountryCode":"+1",
"MobileNumber":2222222
}
}
},
{
"RowId": "3",
"Name": "CCC",
"EmployeeId" : "2342",
"ContactDetails":{
"Address":{
"City": "Vadodara",
"State":"GJ",
"Country":"India"
},
"ContactNumber":{
"CountryCode":"+91",
"MobileNumber":333333333
}
}
},
{
"RowId": "4",
"Name": "DDD",
"EmployeeId" : "09823",
"ContactDetails":{
"Address":{
"City": "Jaipur",
"State":"RJ",
"Country":"India"
},
"ContactNumber":{
"CountryCode":"+1",
"MobileNumber":44444444
}
}
}
]]' doc:name="Set Payload" doc:id="e2910eda-f987-4b85-8cad-ee474b660b77"/>
<ee:transform doc:name="Transform Message" doc:id="675f7027-f893-41dc-896e-4008da78cf86" >
<ee:message >
<ee:set-payload ><![CDATA[%dw 2.0
output application/java
---
payload map (( payload01 , indexOfPayload01 ) -> {
Name: payload01.Name,
EmployeeId: payload01.EmployeeId,
ContactDetails: {
Address: {
City: payload01.ContactDetails.Address.City,
State: payload01.ContactDetails.Address.State,
Country: payload01.ContactDetails.Address.Country
},
ContactNumber: {
CountryCode: payload01.ContactDetails.ContactNumber.CountryCode,
MobileNumber: payload01.ContactDetails.ContactNumber.MobileNumber
}
},
RowID: payload01.RowId
})]]></ee:set-payload>
</ee:message>
</ee:transform>
<bigquery:insert-all doc:name="Insert All" doc:id="4d060baa-93f5-4192-9b7a-73faeff7a926" config-ref="Google_BigQuery_Config" rowsData="#[payload]" tableId="${bigquery.table}" datasetId="${bigquery.dataset}"/>
<logger level="INFO" doc:name="Logger" doc:id="232381b1-f4d1-4690-b7c0-2ccfa2a2f83f" message="#[payload]"/>
<flow-ref doc:name="Flow Reference" doc:id="59982ede-9c37-4630-800f-a5203d32c340" name="asynchronousQueryDataSubFlow"/>
</flow>
<sub-flow name="asynchronousQueryDataSubFlow" doc:id="173d5c84-ede6-40b1-9e8c-eb6e57709779" >
<bigquery:create-job doc:name="Create Job" doc:id="6757a8b4-e3ad-4421-a7c1-630a88ff442a" config-ref="Google_BigQuery_Config">
<bigquery:job-config>
<bigquery:job-configuration>
<bigquery:query-job >
<bigquery:query-string >SELECT * FROM `${bigquery.projectId}.${bigquery.dataset}.${bigquery.table}` WHERE ContactDetails.Address.State in UNNEST (@param)</bigquery:query-string>
<bigquery:named-parameters >
<bigquery:named-parameter-configuration key='#["param"]' >
<bigquery:named-parameter arrayType="true" type="STRING" >
<bigquery:values >
<bigquery:value value="#['MH']" />
<bigquery:value value="#['GJ']" />
</bigquery:values>
</bigquery:named-parameter>
</bigquery:named-parameter-configuration>
</bigquery:named-parameters>
</bigquery:query-job>
</bigquery:job-configuration>
</bigquery:job-config>
<bigquery:job-info />
</bigquery:create-job>
<set-variable value="#[%dw 2.0
output application/java
---
payload.jobId.job]" doc:name="Set Variable" doc:id="0907f02e-c6b3-42bd-9bec-7f24383264f4" variableName="jobId"/>
<flow-ref doc:name="Flow Reference" doc:id="6668a82c-931e-42a4-aac2-f716c31d5704" name="checkJobStatusAndQuerySubFlow"/>
</sub-flow>
<sub-flow name="checkJobStatusAndQuerySubFlow" doc:id="d4dbf4e4-b29f-4f97-93b7-4588243d5f16" >
<bigquery:get-job doc:name="Get Job" doc:id="80dce9f6-5402-4584-a07b-f7115e0fc779" config-ref="Google_BigQuery_Config" jobName="#[vars.jobId]"/>
<set-variable value="#[%dw 2.0
output application/java
---
payload.status.state]" doc:name="Set Variable" doc:id="acd1f279-ef57-4c79-927b-10bd19b6fc3f" variableName="jobStatus"/>
<choice doc:name="Choice" doc:id="60d38791-731d-49ed-916f-e9f4c2e43739" >
<when doc:id="602adbc9-95f6-47a7-a36c-6e6b2f3e7d34" expression="#[vars.jobStatus == 'DONE']">
<logger level="INFO" doc:name="Logger" doc:id="a999b3bd-c637-48c3-8281-50baeca6649b" message="#[vars.jobStatus]"/>
<bigquery:get-query-result doc:name="Get Query Result" doc:id="71055737-7bfa-46bc-bd08-72ae0acd2806" config-ref="Google_BigQuery_Config" jobName="#[vars.jobId]"/>
<ee:transform doc:name="Transform Message" doc:id="d2594838-e547-467d-8e3f-f8e08c2497a9" >
<ee:message >
<ee:set-payload ><![CDATA[%dw 2.0
output application/json
var schema=payload.schema.fields
---
payload.values map ((row, index) -> {
(schema[0].name): row[0].stringValue,
(schema[1].name): row[1].stringValue,
(schema[2].name): {
(schema[2].subFields[0].name): {
(schema[2].subFields[0].subFields[0].name): row[2].value[0].value[0].stringValue,
(schema[2].subFields[0].subFields[1].name): row[2].value[0].value[1].stringValue,
(schema[2].subFields[0].subFields[2].name): row[2].value[0].value[2].stringValue
},
(schema[2].subFields[1].name): {
(schema[2].subFields[1].subFields[0].name): row[2].value[1].value[0].stringValue,
(schema[2].subFields[1].subFields[1].name): row[2].value[1].value[1].stringValue
}
}
})]]></ee:set-payload>
</ee:message>
</ee:transform>
<logger level="INFO" doc:name="Logger" doc:id="bc48d769-f3fa-4644-ba24-218cdc031c12" message="#[output application/json
---
payload]" />
<bigquery:delete-table doc:name="Delete Table" doc:id="b47ffcee-0c58-4081-8425-ff72a205bfab" config-ref="Google_BigQuery_Config">
<bigquery:table table="${bigquery.table}" dataset="${bigquery.dataset}" />
</bigquery:delete-table>
<bigquery:delete-dataset doc:name="Delete Dataset" doc:id="c53bddb2-ae1e-4b9e-a517-344478de7012" config-ref="Google_BigQuery_Config" datasetId="${bigquery.dataset}"/>
</when>
<otherwise>
<logger level="INFO" doc:name="Logger" doc:id="ded8639e-e806-473c-94f2-c47bf4454371" message="#[vars.jobStatus]"/>
<flow-ref doc:name="Flow Reference" doc:id="ad3080a2-8335-4198-a094-e006f6fcd3ae" name="checkJobStatusAndQuerySubFlow"/>
</otherwise>
</choice>
</sub-flow>
</mule>